Putting a model in charge of KV-cache memory
Building an RL environment to learn how KV-cache eviction works in LLM serving systems
I've been reading through how vLLM, SGLang, and NVIDIA's Dynamo handle KV-cache when memory gets tight. The papers are clear enough, but I didn't really understand the tradeoffs until I tried to turn them into code. So I built a small RL environment around the part of the problem I cared about: the inference server is filling up, requests are queueing, and something has to decide what to evict, compress, or swap before the system falls behind.
The setting
Every time an LLM generates tokens, it stores key/value tensors from attention in the KV-cache. A single sequence can occupy hundreds of megabytes. Run enough users in parallel and the GPU eventually runs out of room. When that happens, there are four options, and none of them are free:
- Evict or preempt a sequence — frees memory, but you pay for it later in recomputation, latency, or an outright failed request.
- Compress the cache via quantization (here: fp16 → int8 → int4, halving memory each step).
- Swap to CPU — cheap on the GPU side, slow when the sequence is needed again.
- Do nothing — fine when there's room, dangerous when there isn't.
I wanted a sandbox where a model has to make these decisions explicitly, and where I could later train or evaluate policies without standing up a real serving stack.
Building the simulator
The goal was to capture the actual dynamics of cache management without rebuilding vLLM. Each cache entry is one active sequence:
@dataclass
class CacheEntry:
seq_id: str
tokens_cached: int
sequence_length: int
last_access_step: int
token_gen_rate: float # tokens/step being generated
priority: float # 0-1, higher = more important
block_type: BlockType # system/context/generation/reasoning/ephemeral
quantization_level: QuantizationLevel # fp16/int8/int4
shared_prefix_id: str | None
phase: PhaseType # prefill/decode/reasoning/idle
hotness: float
is_compressed: bool
is_swapped: boolThe two fields that matter most here are block_type and shared_prefix_id.
Real serving systems don't treat all KV-cache the same, and once you look at it the reason is obvious. A system prompt gets reused on every turn — evicting it would be a disaster. Reasoning tokens are the opposite: once the thinking phase ends, nothing reads them again. Following the categorization in NVIDIA's Dynamo blog on agentic inference, I tagged blocks by how likely they are to be reused:
BLOCK_TYPE_EVICTION_VALUE = {
"system": 0.0, # highest reuse, never evict
"context": 0.25, # conversation history — high reuse
"generation": 0.5, # active generation — moderate reuse
"reasoning": 0.9, # thinking tokens — near-zero reuse after completion
"ephemeral": 1.0, # subagent/temp — zero reuse, safe to evict
}In practice, a lot of sequences in a batch share the same system prompt. vLLM's block-based cache manager and automatic prefix caching reuse those prefix blocks instead of recomputing them; SGLang gets a similar effect through RadixAttention. The non-obvious consequence is that evicting a sequence which shares its prefix with five others can free almost nothing, because the prefix pages are still pinned by the other references.
Memory cost tracks paged allocation with quantization:
def memory_cost(self, cache_capacity, page_size=128):
if self.is_swapped:
return 0.0
physical_tokens = self.allocated_pages(page_size) * page_size * self.quantization_multiplier()
return physical_tokens / cache_capacityEach step, the simulator generates tokens for active sequences, tries to admit pending requests (and fails them after 5 steps of waiting), spawns new arrivals, and lets some sequences complete. The agent observes memory usage, cache entries ranked by cost, pre-scored eviction candidates, and queue pressure, and then acts.
The reward
For the environment and eval stack I used Prime Intellect's tooling, specifically Verifiers, their framework for building RL environments with tool use. The environment is a StatefulToolEnv: the model calls cache-management tools, the simulator advances a step, and reward functions score the episode at the end.
Getting the reward right took more iterations than I'd like to admit. The recurring problem was that eviction frees memory and prevents failures, but it also kills throughput. Every reward component encodes one side of a tradeoff, and the policy has to learn to balance them.
rubric.add_reward_func(failure_penalty, weight=0.40)
rubric.add_reward_func(throughput_reward, weight=0.25)
rubric.add_reward_func(headroom_bonus, weight=0.18)
rubric.add_reward_func(memory_efficiency, weight=0.07)
rubric.add_reward_func(eviction_quality, weight=0.05)
rubric.add_reward_func(latency_penalty, weight=0.03)
rubric.add_reward_func(risky_eviction_penalty, weight=0.02)Failure penalty (weight: 0.40)
In real serving, failures cascade. One rejected request creates backpressure that causes more, and the system degrades quickly from there. The penalty mirrors that with an accelerating cost:
penalty = min(failures * 0.15 + max(0, failures - 2) * 0.1, 1.0)The first two failures cost 0.15 each. After that, every additional one costs 0.25. So 1 failure = -0.15, 3 = -0.55, 5 = -1.0 (capped). I started with a flat per-failure penalty and it didn't work — it treated "one unlucky timeout" the same as "the server is overloaded," which gave the policy no reason to prevent the cascade in the first place.
Throughput reward (weight: 0.25)
This is what stands between the policy and the trivial "evict everything" strategy. It rewards total tokens generated across the episode, normalized against a realistic ceiling:
normalized = min(total_tokens_generated / 500.0, 1.0)At 0.25 it pulls directly against the failure penalty. The policy has to keep enough sequences alive to actually produce tokens while freeing enough memory to avoid the cascade.
Headroom bonus (weight: 0.18)
This one is about being proactive instead of reactive. Rather than scoring the final state, it samples memory usage at every step:
for usage in memory_history:
if usage < 0.8:
headroom_scores.append(1.0) # excellent
elif usage < 0.95:
headroom_scores.append(0.5) # acceptable
elif usage < 1.0:
headroom_scores.append(0.2) # tight
else:
headroom_scores.append(-0.5) # over budget
return (sum(headroom_scores) / len(headroom_scores)) * 0.4If you only reward the final memory state, the policy learns to dump everything in the last step. Averaging across the episode forces it to maintain headroom continuously, which is what actually prevents failures. A step below 0.8 usage scores 5x more than one at 0.98 — the curve is intentionally aggressive about staying clear of the ceiling.
Eviction quality (weight: 0.05)
Not every eviction is equal. Evicting an ephemeral block is nearly free; evicting a system prompt is catastrophic. This reward looks at what's *left* in the cache at the end:
for entry in cache.values():
remaining_value += (1.0 - entry.eviction_value) * entry.memory_cost(cache_capacity)
normalized = remaining_value / memory_usageA higher score means the policy kept the high-value blocks (system, context) and dropped the low-value ones (reasoning, ephemeral). I weighted it low on purpose — the block-type signal should emerge naturally from the failure and throughput rewards. This is just a nudge.
Risky eviction penalty (weight: 0.02)
A targeted penalty for specifically bad eviction decisions. It tracks each eviction and penalizes based on what was dropped:
if block_type == "system":
penalty += 0.3 # evicting a system prompt is always wrong
if block_type == "context" and priority >= 0.5:
penalty += 0.15 # high-priority context is expensive to lose
if block_type == "generation" and priority >= 0.7 and progress >= 0.7:
penalty += 0.2 # nearly-complete high-priority generationDeliberately small weight. It's a guardrail, not the primary signal. The policy is supposed to learn this from the other rewards; this just catches the cases where eviction quality is too blunt to fire.
Latency penalty (weight: 0.03) and memory efficiency (weight: 0.07)
The latency penalty pushes back on swap-to-CPU abuse: min(total_swap_latency * 0.2, 0.3). Swapping is a valid tool, but it isn't free — each CPU access adds 0.1–0.3 latency. Without this, the policy just swaps everything instead of making real eviction decisions.
Why these weights
The shape of the weights is a priority ordering: avoid failures first, maintain throughput second, manage memory proactively third, everything else is refinement. The top three (failure, throughput, headroom) account for 83% of the reward. The remaining 17% is there to sharpen targeting and prevent the policy from drifting into degenerate strategies like swap-everything.
They also have to produce a *learnable* reward landscape, which is the part that's easy to underestimate. Push the failure penalty too high and the policy collapses into "evict everything" and throughput tanks. Push throughput too high and it hoards sequences until failures spike. The balance point is where the policy has to actually reason about which sequences to keep based on block type, priority, and pressure level.
Results
The rewards above are the version that worked, but I only got there after spending a couple of sessions chasing what looked like a bad policy and turned out to be three environment bugs:
- The compress action was a no-op past the first call — a hardcoded multiplier silently ignored int4.
- The system prompt enforced one tool call per step, so the model couldn't keep up with memory growth even if it wanted to.
- Throughput normalization was 15x too high, which flattened the gradient signal into nothing.
Fixing those changed the reward landscape entirely. Same model (gpt-5.4-mini, zero-shot), same eval, before and after:
| metric | before | after |
|---|---|---|
| reward | -0.090 | +0.043 |
| failures per episode | 7.0 | 1.0 |
| pressure steps | 7.6 | 1.2 |
| tool calls per turn | 1.0 | 2.9 |
| evict calls | 6.8 | 17.4 |
| compress calls | 5.0 | 14.4 |
| throughput reward | 0.037 | 0.139 |
| headroom bonus | 0.081 | 0.321 |
This isn't a trained policy yet — I ran zero-shot first because it's the fastest way to check whether the environment is giving the model a usable control problem to begin with. Failures dropped from 7 to 1. Pressure went from half the episode to almost nothing. Compress usage nearly tripled once it actually had an effect. The model averaged ~3 actions per turn, mixing eviction and compression based on the current pressure level instead of repeatedly calling one tool.
Full rollout breakdown from prime eval run:
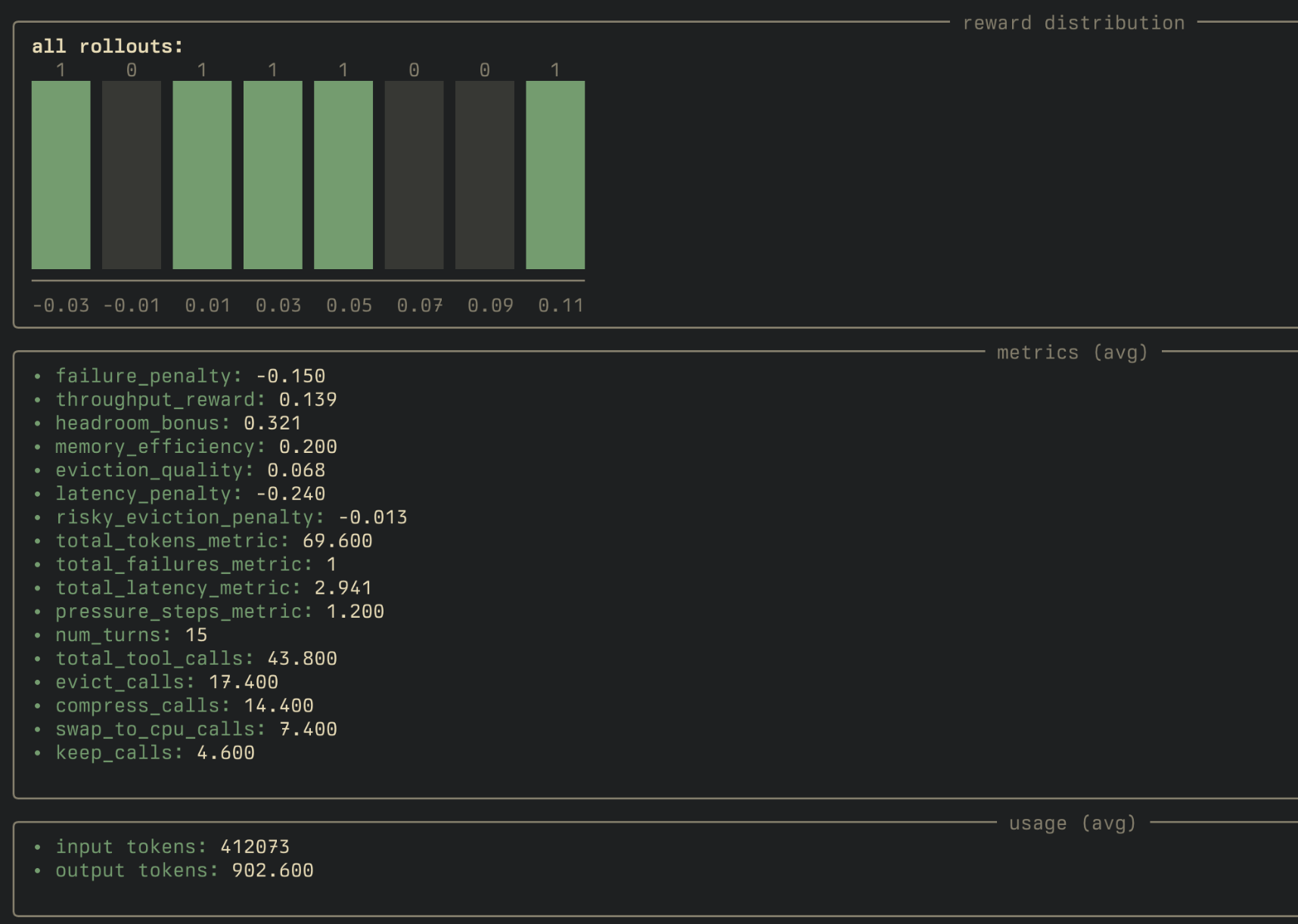

Takeaways
A few things that became much clearer through building the simulator than from reading about them:
- Block types carry most of the weight. A system prompt and a reasoning trace can occupy the same number of bytes and have very different reuse profiles. Treating them uniformly is the easy way to make bad decisions.
- Shared-prefix deduplication makes eviction non-local. The memory you free by evicting a sequence depends on what else references the same prefix pages. The papers mention this, but it's easy to underestimate until you've watched a free release nothing.
- KV-cache compression is underrated. In the simulator, FP16→INT4 is a clean 4x. Real systems are messier — kernels, calibration, quality tolerance — but under moderate pressure, compression is often a better first move than dropping the request and recomputing later.
- Action-space constraints have to match the system dynamics. One action per scheduling cycle sounded clean and turned out to be infeasible under sustained load. Real serving systems make multiple decisions per cycle for the same reason.
The environment code is on GitHub if you want to try it.